Understanding captioning and subtitles
Bharat Kalluri / 2021-03-28
Subtitles are one of those things which you might think is very simple and straight forward, but dive in to the field to only realize it's a lot more complicated.
Fun fact, The word subtitle is the prefix sub- ("below") followed by title. In some cases, such as live opera, the dialogue is displayed above the stage in what are referred to as surtitles (sur- meaning "above").
The SRT specification
srt files are one of the most popular captioning formats currently. All major video players support
srt files. If you have added subtitles to a video on VLC, it would have probably been a srt file.
The problem is that there is not established standard for srt. Here are the rules a srt file should
follow so that players can read them. First up, let us look at a sample
1
00:02:17,440 --> 00:02:20,375
Senator, we're making
our final approach into Coruscant.
2
00:02:20,476 --> 00:02:22,501
Very good, Lieutenant.
There are 4 rules an srt file is expected to follow
- The first line should be an incrementing index
- Immediately after that, there should be another line which contains two timestamps. in the format HH:MM:SS,MILLSEC
separated by
-->. Another fun fact, the reason the separator is comma is because the creators were based out of France! - After this, there can be one or more lines of text containing the actual contents of the caption
- A new line is expected to be between each block
These blocks are also called as cues.
The spec sounds very simple, and it is. So, my initial idea is to implement a parser using just RegEx. This is how that would look
from pprint import pprint
CUE_BLOCK_REGEX = r'((?P<index>[0-9]+)\n)?(?P<start_time>[0-9]{2}:[0-9]{2}:[0-9]{2}.[0-9]{3}) --> (?P<end_time>[0-9]{2}:[0-9]{2}:[0-9]{2}.[0-9]{3})\n(?P<content>.*?)(\n\n|$)'
sub_to_parse = '''1
00:02:17,440 --> 00:02:20,375
Senator, we're making
our final approach into Coruscant.
2
00:02:20,476 --> 00:02:22,501
Very good, Lieutenant.'''
pprint([m.groupdict() for m in list(re.finditer(CUE_BLOCK_REGEX, sub, re.DOTALL))])
"""
[{'content': "Senator, we're making\nour final approach into Coruscant.",
'end_time': '00:02:20,375',
'index': '1',
'start_time': '00:02:17,440'},
{'content': 'Very good, Lieutenant.',
'end_time': '00:02:22,501',
'index': '2',
'start_time': '00:02:20,476'}]
"""
Parsing issues with Regex
Well, as I was saying. There is no formal specification surrounding srt. So different files follow
different structures. There is a great article on blog.foolip.org
which analyzed around 10000 srt files from open subtitles. Here are some highlights from that article
- The ID line is mostly useless, some
srtfiles skip it entirely - Assuming blank lines separate cue's turns out to be unreliable
- The timestamps also do not seem to follow a specific format, the padding may not be proper. Assuming milliseconds to always be a 3 padded integer would probably cause issues. I do not intend on dealing with this in my implementation.
- HTML tags could also be broken, there could be a <b> tag with no closing tag available.
I'm sure we can have a RegEx which can support all of these quirks and still extract cue data. I think at that point, the RegEx solution will be much harder to read. So, I opted to write the parser in python instead
Round II: SRT parser in Python
All the code for this is present on Github
Looks like Rule 1 (incrementing index) and Rule 4 (A new line after a cue) are not consistently followed. So, let us ignore those and try building a parser. Two points which we can depend on are that
- There will be a line which will have
-->which will contain start and end timestamps - Right after this, there will be one or more lines of content
Here is the game plan, filter all empty lines and filter all the lines with numbers (lines with the ID). After that, we will be left with just the lines having timestamps followed by content. Now, group by the lines with the timestamps, and the output will be just alternate blocks of timestamps and content.
Now, it is just a matter of putting these blocks together to get the cue objects.
Before this, let us create a class called CueBlock
from utils import convert_str_time_to_timestamp_in_ms
class CueBlock:
def __init__(
self, index: int, start_time_str: str, end_time_str: str, content: str
) -> None:
self.index = index
self.start_time = convert_str_time_to_timestamp_in_ms(start_time_str)
self.end_time = convert_str_time_to_timestamp_in_ms(end_time_str)
self.content = content.strip()
def to_json(self):
return {
"index": self.index,
"start_time": self.start_time,
"end_time": self.end_time,
"content": self.content,
}
We are also importing a helper function which converts string timestamp into milliseconds.
Some helper functions before we get started
from typing import Iterator
def convert_str_time_to_timestamp_in_ms(time_str: str) -> int:
split_on_comma = time_str.split(",")
ms = int(split_on_comma[1])
hours, minutes, seconds = map(int, split_on_comma[0].split(":"))
return ms + (seconds * 1000) + (minutes * 60 * 1000) + (hours * 60 * 60 * 1000)
def is_line_with_timestamps(line_contents: str) -> bool:
return '-->' in line_contents
def str_iter_arr_to_single_line(str_iter: Iterator[str]) -> str:
return '\n'.join([str(g) for g in str_iter])
Now, implementing the parser function
def get_cue_blocks_from_srt_string(srt_string: str):
all_cue_blocks = []
cue_count = count(0)
srt_lines: [str] = srt_string.splitlines()
filter_numbers: Iterator[str] = filter(lambda x: not x.isdigit(), srt_lines)
filter_empty_lines: Iterator[str] = filter(lambda x: len(x) > 0, filter_numbers)
groupby_iter: Iterator[tuple[bool, Iterator[str]]] = groupby(filter_empty_lines, is_line_with_timestamps)
for key, group in groupby_iter:
current_line = str_iter_arr_to_single_line(group)
if is_line_with_timestamps(current_line):
timestamp_data_str = current_line
regex_matches: dict[str, str] = re.match(
TIMESTAMPS_REGEX,
timestamp_data_str,
re.DOTALL
).groupdict()
cue_contents = str_iter_arr_to_single_line(next(groupby_iter)[1])
all_cue_blocks.append(
CueBlock(
start_time_str=regex_matches.get('start'),
end_time_str=regex_matches.get('end'),
content=cue_contents,
index=next(cue_count)
).to_json()
)
return all_cue_blocks
Let us go through the code of get_cue_blocks_from_srt_string step by step
- The input is the raw string from the
srtfile, the first step is to split them into lines - After that, we first filter out all the lines which just contain a number. These are the lines which contain ID's. We will be populating them manually later on.
- Next, filter out empty lines. To skip all the new lines which are there to signify cue block end.
- Now that we just have timestamps and content. We run a
groupbyon the array to form alternating blocks of timestamps and content. If this does not make sense, I suggest putting a print here and seeing what the output ofgroupbyis. - Remember that
groupbygives back an iterator, this will prove very useful very soon. - Now, get the current line (It will be an iterator of string, we join all those using new lines. This is because
content can span multiple lines). If current line contains
-->then it is a line which has timestamps. - If the current line contains timestamps, then the next block in the group by will contain content. So, we call
nexton the iterator to get the subtitle contents. - Now that we know the contents, and the timestamps line, it's just a matter of parsing the timestamps line using some regex's to figure out the start time and end time and make a CueBlock out of this information
- And push all these CueBlock objects to an array. At the end, we return this
CueBlocks array.
That's it! This is a basic srt parser.
All the code for this is present on Github
What more?
This is where the coding piece ends. I was curious to see how complicated captioning, and the software surrounding it is.
Subtitle formats
Subtitles are also called as timed tracks. And there are a lot of competing formats in this space. This is what happens
when there is no standard. Currently there are over 50 competing formats!
Looks like srt is the most popular between all of them, most probably because of its simplicity.
Some formats use frame numbers as a reference, this could be a huge problem since there will be the same video in different frame rates and that could break the subtitles.
Additional features supported by different Captioning specifications
Also, positioning should be a part of the spec. Subtitles cannot be shown always at the bottom, if there is something
important going on at the bottom end of the screen. The sub will shadow that. As far as I know srt does not support this.
Another thing which needs to be included is the color. This can be achieved through html tags. Some players just do it in white with a black back shadow. That seems to mostly work as well. All the media players need to support some level of HTML tags.
Positioning and its importance
This gets more interesting, I thought the subtitles are usually either placed on the top or the bottom of the screen. Looks like japanese subtitles are placed on the right and left ends of the screen instead of top or bottom.
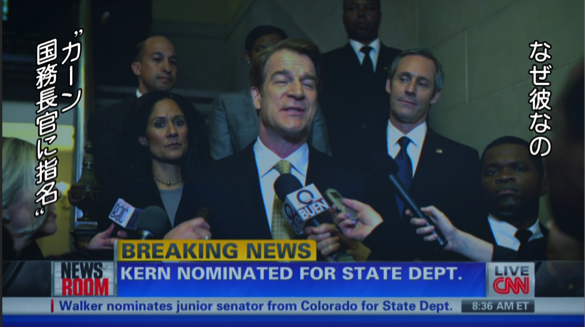
Forced Narrative
All captions are not created equal. Imagine you are watching an english movie which has some parts in italian. Even though the subtitles are switched off, Netflix will show subtitles for the parts which are in italian. This is called as forced narrative.
This is decided by the movie-makers. If the character in the movie does not know the language, then the director can choose not to show FN captions because they want you to see the world as the character sees it.
Captioning software
Of course there are services which will auto subtitle videos. For example, Veed
Captioning software is not cheap either, MacCaption starts from 1898$, and the enterprise edition goes up till 15525$. EZtitles starts from 1,720 € and goes up to 2,380 €.
Law
This blew my mind. Apparently there are laws surrounding captioning. It is a part of the "Americans with Disabilities" act, "Rehabilitation Act" and "21st Century Communications and Video Accessibility Act" that captioning is mandatory!
That is the reason why all US material on Amazon Prime and Netflix etc have captions.